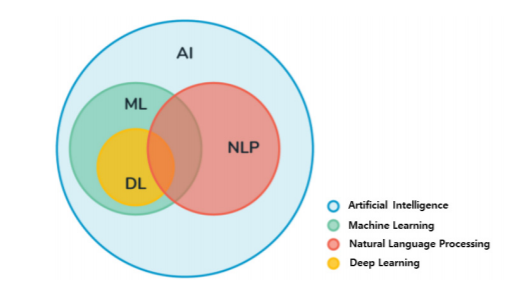
자연어처리(Natural Language Processing)은 머신러닝과 딥러닝의 교집합 그 어드메라고 부를 수 있는 분야다. 그림으로 표현한다면 아래처럼 볼 수 있겠다. 이러한 NLP의 세부 분야로는 감성분석 또는 감정분석, 의미 분석, 구문분석, 음성인식(질의응답) 등이 있다. 개발 환경은 아나콘다, 필요한 프레임워크는 아나콘다를 설치하면서 기본적으로 딸려오는 Numpy, Pandas, Jupyter notebook, scikit-learn, matplotlib, seaborn, nltk 등 외에 tensorflow, keras, gensim 이 세 가지만 별도로 아나콘다 프롬프트 창에서 pip를 통해 설치해야한다. - tensorflow 설치 pip install tensorflow 텐서플로우는 ..